
BigQueryのパーティショニングとシャーディング
テーブル分割の必要性
みなさんBigQuery使っていますか??私は使っています!!
データエンジニアのような職種の方なら一度は触ったことがあるであろう、Google Cloudで提供されているBigQueryですが、よく意味を間違って使われていたりする言葉や、実施すればパフォーマンスが上がるのに実施されていない処理があるように見受けられます。
今回タイトルにもなっている パーティショニングとシャーディング はまさにそれに該当する用語で、インターネットを回遊しているとシャーディングのことをパーティショニングと呼んでいるような記事も散見されます。
とはいえ私自身も認識を間違っていたらまずいので、今回、改めて調べ直して纏め直します。
いずれもBigQueryで特にログ系のテーブルのような大きなテーブルを扱う場合には必須の内容かと思います。
パーティショニングとシャーディング
パーティショニングとシャーディングについては、Google Cloudの公式ドキュメントにまさにドンピシャの記述があります。
基本的にはこの記事の内容を正しく読み込めていれば問題無いです。
重要なのは、
テーブル シャーディングは、
[PREFIX]_YYYYMMDDなどの名前の接頭辞を使用して複数のテーブルにデータを格納する方法です。
パーティション分割テーブルのほうがパフォーマンスが向上するため、テーブルのシャーディングよりもパーティショニングをおすすめします。シャーディングされたテーブルでは、BigQuery は各テーブルのスキーマとメタデータのコピーを保持する必要があります。BigQuery では、クエリされた各テーブルの権限の検証も必要になる場合があります。この方法はさらに、クエリのオーバーヘッドを増やし、クエリのパフォーマンスを低下させます。
ここです。
つまり、 シャーディングは、 接頭辞の末尾に日付等を付与 しまとめて扱えるテーブル 群 を作ること、パーティショニングは一つの テーブルの内部でセグメント(=パーティション)に分割 することでクエリパフォーマンス向上・クエリの読み取り対象データ量の削減に繋げるということです。
シャーディングの場合はテーブルをまとめたものでしかないので、スキーマやメタデータについてはこの群の中のテーブル全てで保持することになります。
非常にややこしいですが、日常会話でお互いの認識がズレているとよくないので、BigQueryユーザーの皆様、ぜひこのタイミングでご認識いただければと思います。
実際にBigQueryで確かめてみる
百聞は一見にしかず、ということで、実際にテーブルを作って確かめます。
テーブル作成
まずは、シャーディングの対象となるテーブル群を作ってみます。
CREATE TABLE `sandbox.TEST_20230301` AS SELECT 1 AS sample_column, DATE(2023, 3, 1) AS sample_date; CREATE TABLE `sandbox.TEST_20230302` AS SELECT 2 AS sample_column, DATE(2023, 3, 2) AS sample_date;
この例では、 sandbox データセット内に TEST をprefixとするテーブルを二つ作っています。
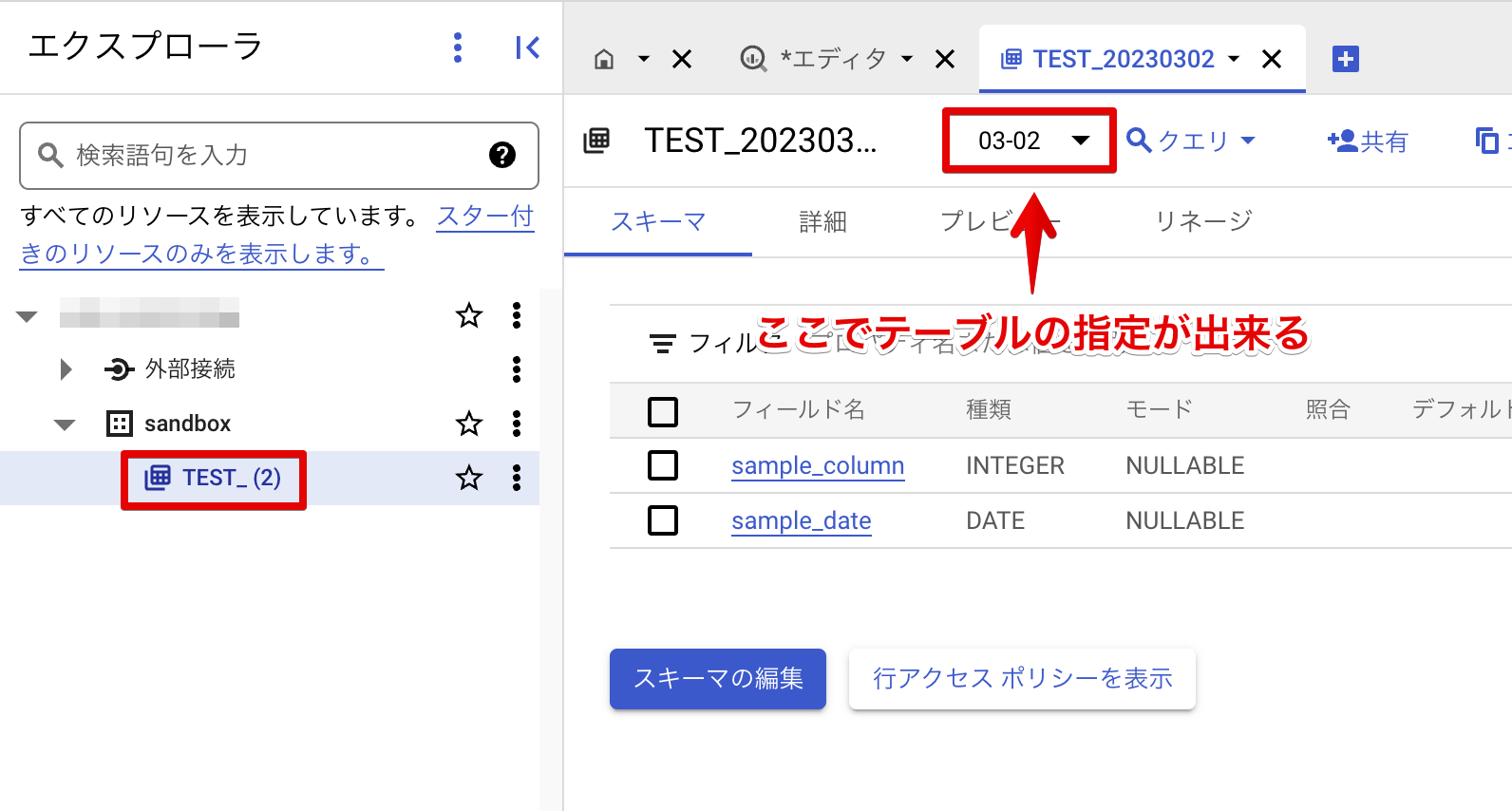
実際に走らせてみると…下記の画像のようにBigQueryのエクスプローラ上の表示でまとまっています。また、GUI上からテーブル群に含まれる個々のテーブルの指定が可能です。
続いてパーティションテーブルを作ってみます。
CREATE TABLE `sandbox.TEST_PARTITIONED` PARTITION BY sample_date AS ( SELECT 1 AS sample_column, DATE(2023, 3, 1) AS sample_date UNION ALL SELECT 2 AS sample_column, DATE(2023, 3, 2) AS sample_date );
このように、 PARTITION BY でパーティショニングに使用するカラムを指定します。
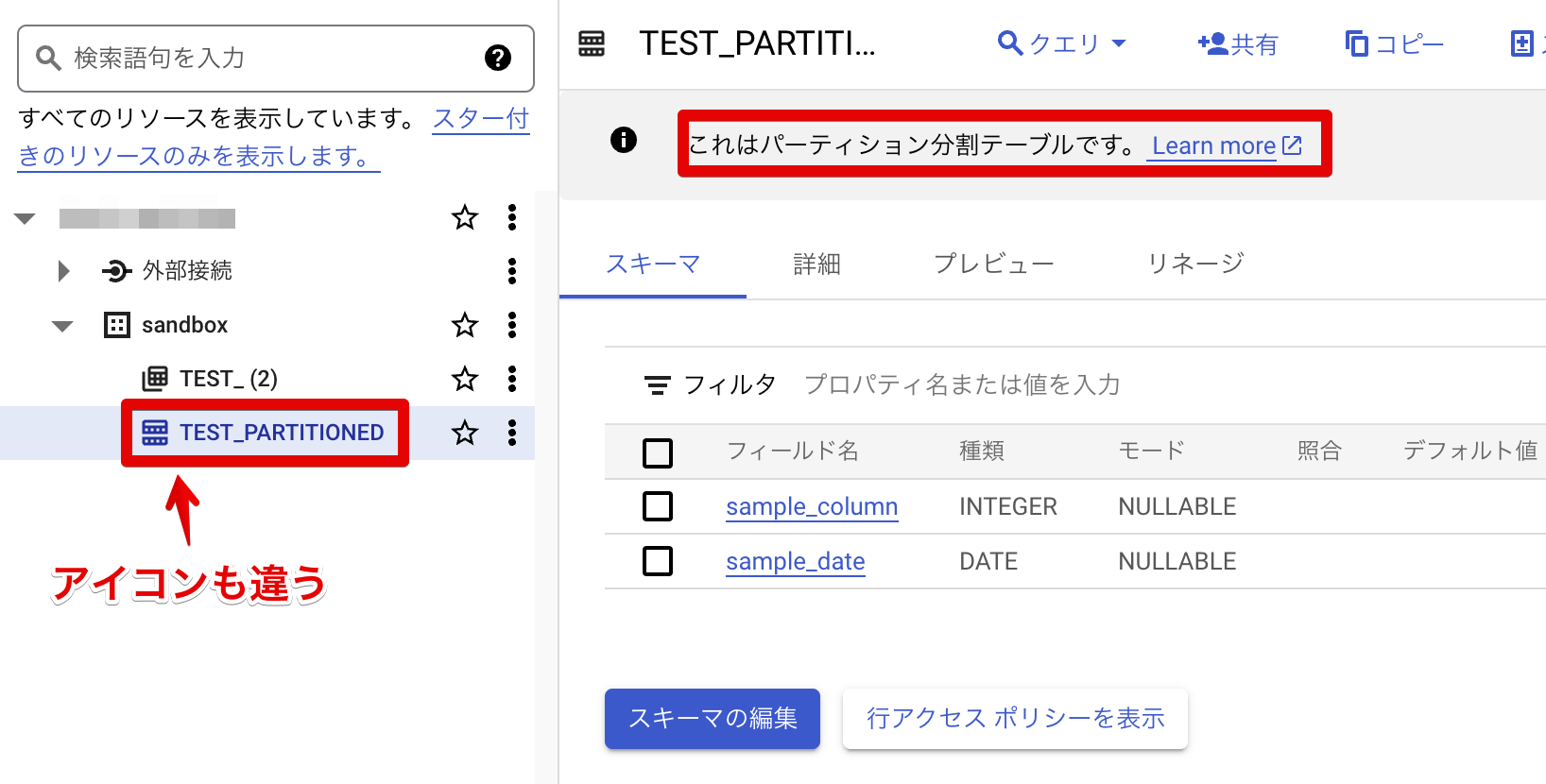
作成してみると、下記の画像のように微妙にいつものテーブルと違うアイコンが表示されます。
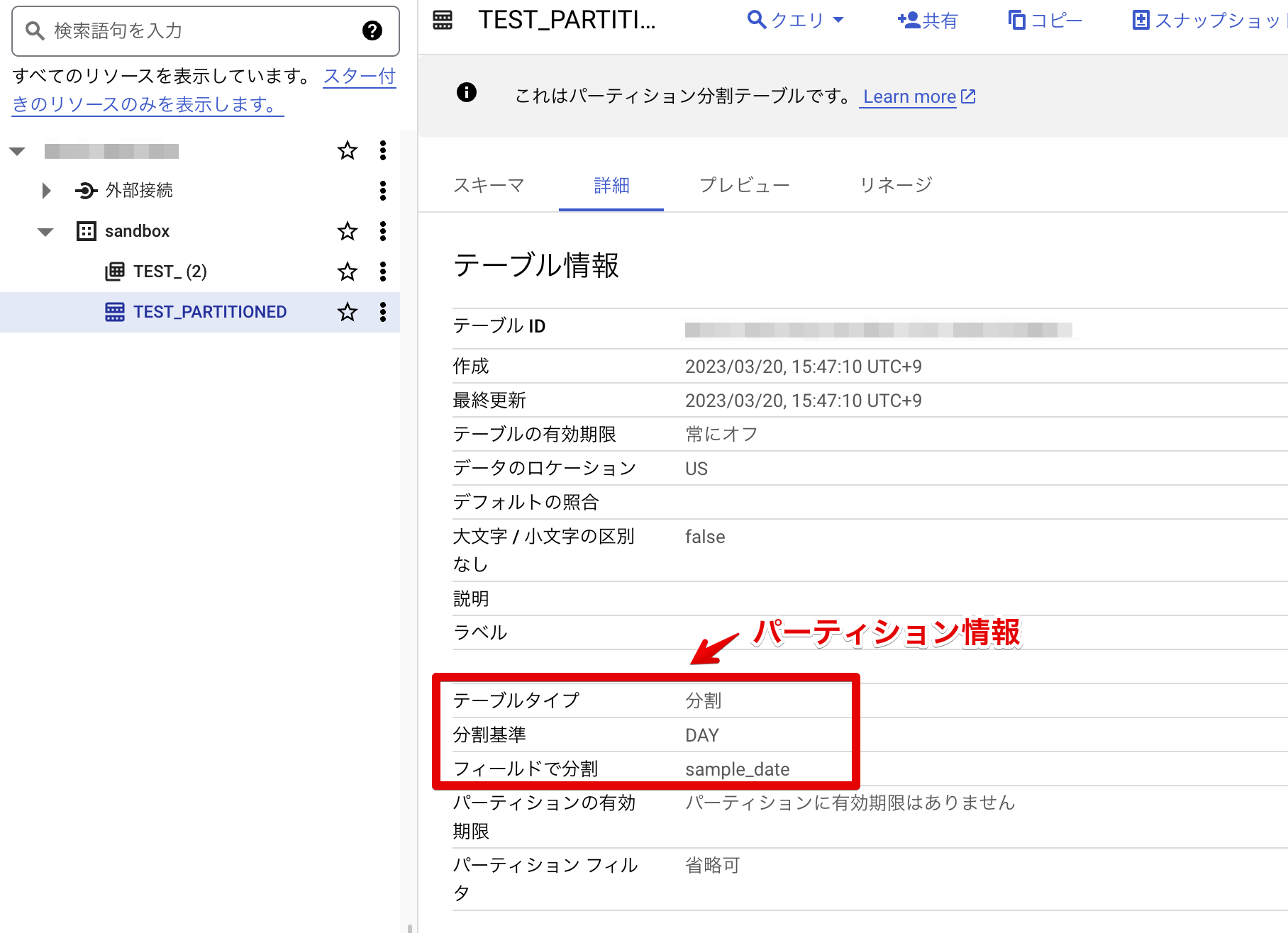
詳細を見ることで、どのようにパーティショニングが行われているかの確認もできます。
BigQueryに慣れていない頃はこれらのアイコンの差に気付かないかもしれませんが、それぞれに意味があることを抑えておくと良いかと思います。

クエリの実行
ここからは実際のクエリを見ます。
たとえば、先ほど作成したテーブルで sample_column が 2 の日付を見つけたいとします。
シャーディングを行っているテーブルに対してクエリを走らせる際は、 * によるワイルドカードテーブルクエリ が使えます。ワイルドカードテーブルクエリの公式ドキュメントはこちらです。
SELECT * FROM `sandbox.TEST_20*` WHERE sample_column = 2
TEST_*ではなく TEST_20* を指定している理由ですが、
実は TEST_* とすると、 TEST_NORMAL や TEST_PARTITIONED も拾ってしまい、
Wildcard table over non partitioning tables and field based partitioning tables is not yet supported,
という内容のエラーが発生します。
なので実を言うと重複するprefixを設定すること自体が好ましくありません。(今回はデモなので適当に作りましたが)
パーティションテーブルの場合はもっとシンプルに、普通のクエリを書くだけです。
SELECT * FROM `sandbox.TEST_PARTITIONED` WHERE sample_column = 2
が、パーティションに使用したカラムでフィルタを行うことでスキャンする対象のデータ量を減らすことが出来ます。


こうして見ると一目瞭然ですね。
もちろん、これはシャーディングの場合も直接テーブルをワイルドカードを使わずに指定するか、 _TABLE_SUFFIX としてテーブルを指定することで対応出来ます。例えば、
SELECT * FROM `sandbox.TEST_20*` WHERE sample_column = 2 AND _TABLE_SUFFIX = '230302'
等です。
個人的には、クエリにBigQuery特有の概念を登場させずに扱えることや、メタデータの複数所持が微妙、という観点から可能な限りパーティションテーブルを利用しています。
クラスタリング
パーティショニングを行うことでクエリパフォーマンスを上げられるというのは述べた通りですが、さらにクラスタリングと呼ばれる処理でクエリパフォーマンスを詰めることが出来ます。
クラスタリングについても公式ドキュメントがかなり参考になりますので、詳細な仕組みはこちらを参照いただくとして…
特に注意したいのは下記の点かと思います。
-
コストについてはパーティショニングに比して正確に見積もれない
-
パーティショニングと併用することでさらにパフォーマンスを上げられる
特定のカラムを組み合わせてのフィルタをよく行う場合などには設定すると良いとされています。
パーティショニングの制約
シャーディングよりパーティショニングを使用しましょう、という話になってはいますが、パーティショニングにおいては、ひとつ、必ず気にしておくべき大きな制約 があります。
それは上限があり、2023年3月現在、4000とされていることです。上限についても公式ドキュメントにて言及がありますのでチェックが必要です。
またこの現在の4000、という数字がなんとも判断が難しいところ…なのですが、日ごとにパーティショニングを行う場合で10年分以上のデータが入るというのが一つの目安になるでしょうか。
過去データ等で既に10年が見えている場合はパーティショニングの単位( DAY , HOUR , MONTH , YEAR が現時点では選択できます)の調整での対応を行うか、パーティションに有効期限を設定出来る ので、そのあたりも活用できるかと思います。
まとめ
この記事では、BigQueryを扱う上でよく出てくる「パーティショニング」「シャーディング」「クラスタリング」について触れていき、実際にBigQueryの画面で確認してみました。
どっちがどっちだっけ…?となりやすいですが、いずれもBigQueryで設計する上では意識しておきたい要素ですので、正しい認識を持っておきたいですね!
