
Snowpipeでデータ分析基盤Snowflakeへデータロードする方法
ABCではテレビ視聴データ(視聴者非特定視聴データ)・動画配信ログ・ウェブアクセスログなどのデータ分析基盤としてSnowflakeを活用しています。
Snowflakeには、データロードの手法として「Snowpipe」という機能が提供されています。
このSnowpipeを利用することで、クラウド(AWS・GCP・Azure)へのデータ保存がトリガーとなり、Snowlfakeへ自動的にデータロードが可能になります。
そこでデータ分析基盤において、データレイクをAWS S3とし、Snowpipeの設定を行いました。
AWS S3にログが保存されると、Snowpipeを経由してSnowflakeへデータが自動的に取り込まれるという構成ですね。
自動でデータロードを行ってくれるSnowpipeですが、その設定はAWSとSnowflake間で行う必要があり、やや煩雑な作業に。
そのため設定方法について整理し、以下にまとめてみました。
Snowpipeの設定方法
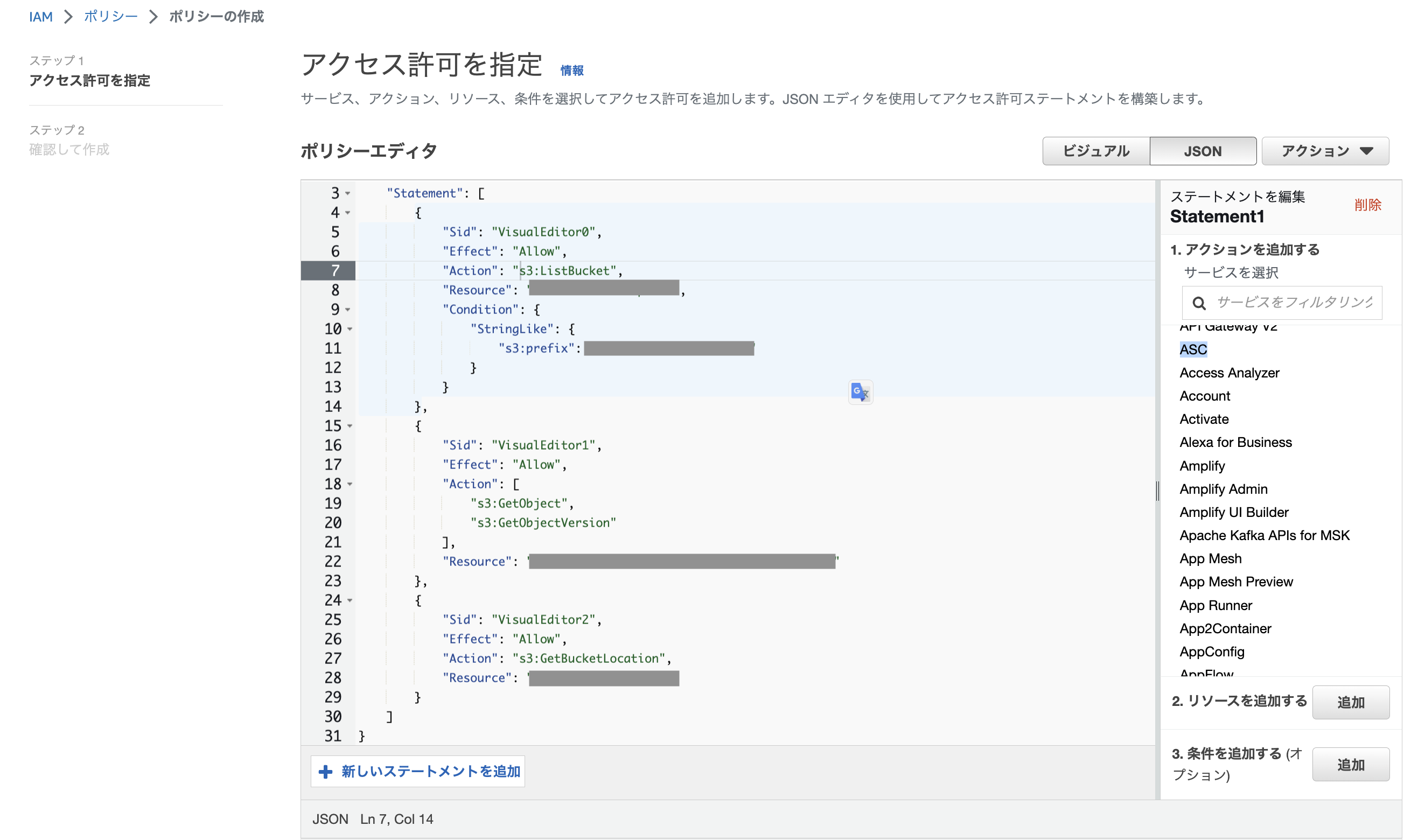
IAMロールにアタッチするポリシーを作成
Snowpipeの設定にIAMロールが必要となるため、まずはデータレイクとなるS3バケットへの権限を付与したポリシーを作成します。
IAMロールを作成しポリシーをアタッチ
次にIAMロールの作成。作成後は先ほどのポリシーをアタッチしましょう。
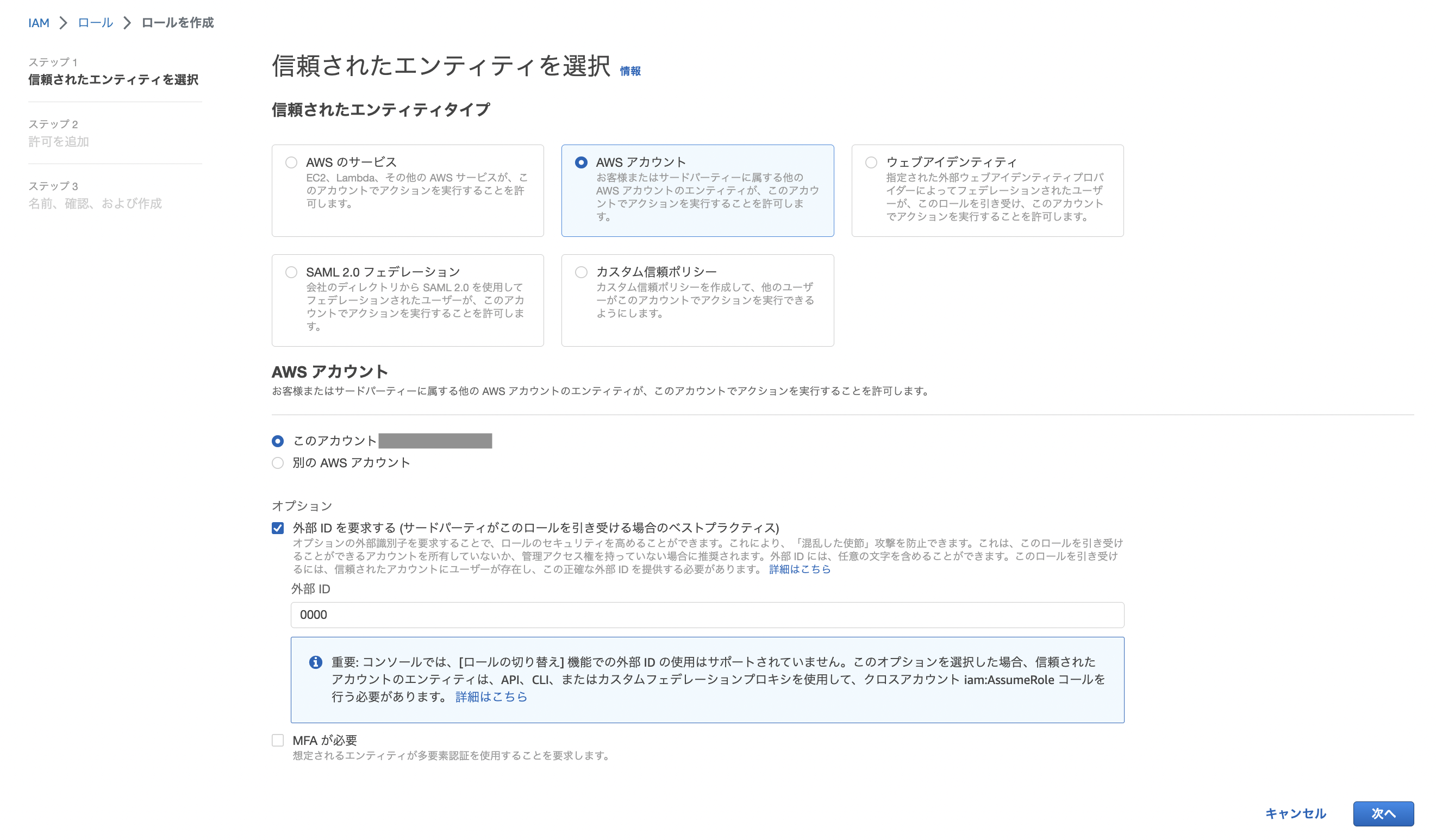
なお、AWSリソースをサードパーティー(Snowflake)に許可するには外部IDが必要となるのですが、一旦ダミー「0000」とします。
IAMロールを指定したストレージ統合を作成
ここからはSnowflakeでの作業。IAMロールを指定してストレージ統合を作成します。
-- ACCOUNTADMINにて実行 USE ROLE ACCOUNTADMIN; CREATE STORAGE INTEGRATION hoge TYPE = EXTERNAL_STAGE STORAGE_PROVIDER = S3 ENABLED = TRUE STORAGE_AWS_ROLE_ARN = '先ほど作成したIAMロールのARN' STORAGE_ALLOWED_LOCATIONS = ('s3://<データレイクとなるS3バケット>');
ストレージ統合とは、S3などのクラウドストレージにアクセスするオブジェクトのこと。
このオブジェクトにIAMロールを設定することで、S3からのデータ取得を可能にしているということですね。
ストレージ統合からSnowflakeアカウントのIAMユーザーと外部IDを取得
DESC INTEGRATION hoge;
ストレージ統合の情報を表示させます。
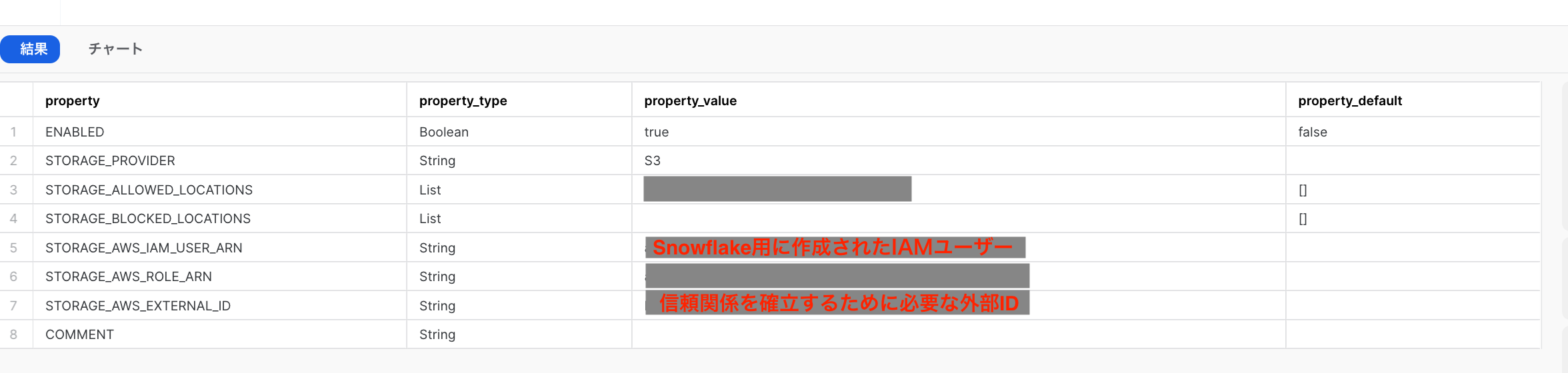
必要な情報はSTORAGE_AWS_IAM_USER_ARNとSTORAGE_AWS_EXTERNAL_IDの2つ。
コピーしておきましょう。
AWS IAMロールの信頼ポリシーを変更
それではAWSへ戻ってIAMロールの信頼ポリシーを変更します。
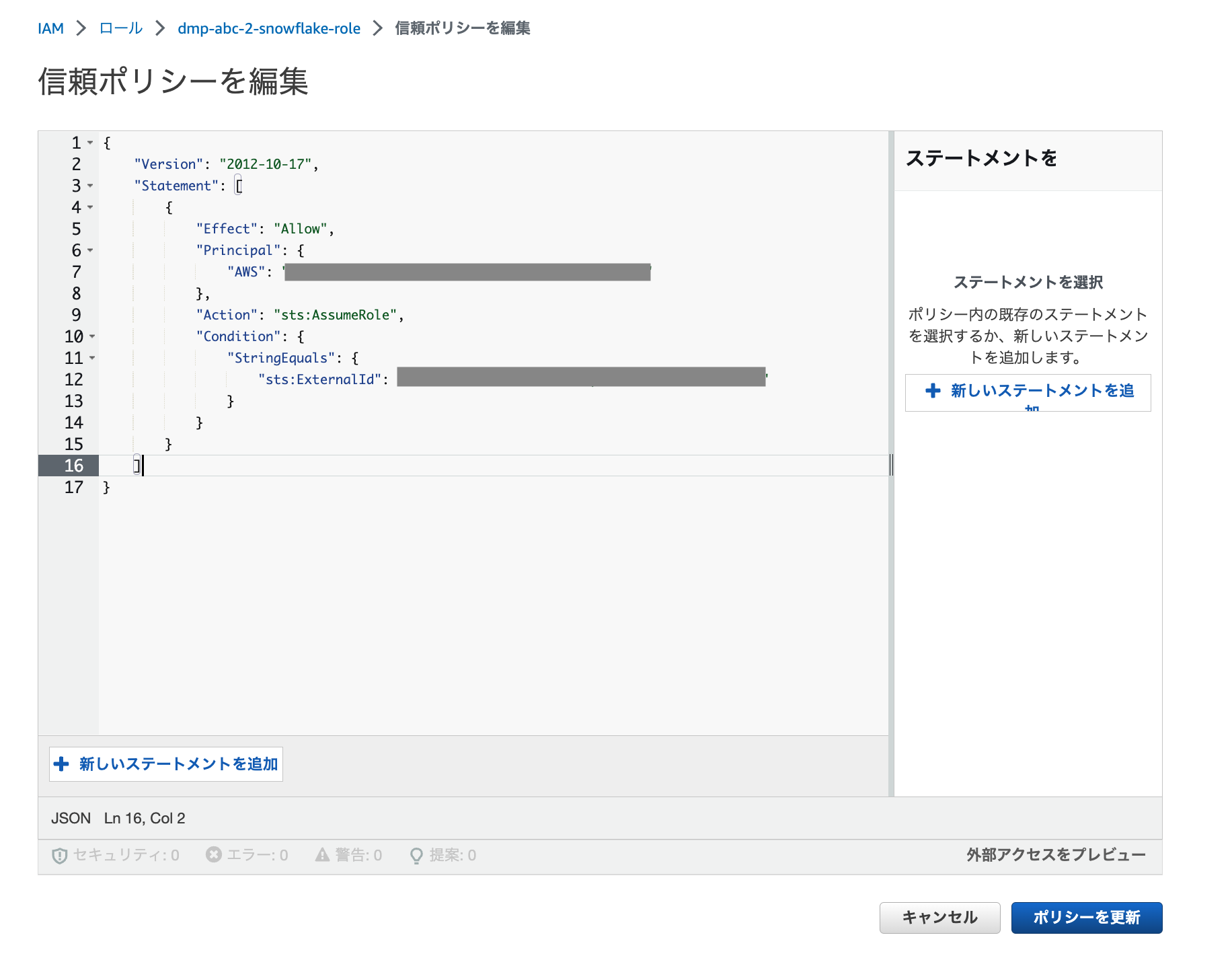
先ほどコピーしたSTORAGE_AWS_IAM_USER_ARNを”AWS”、STORAGE_AWS_EXTERNAL_IDを”sts:ExternalId”に設定。
ステージとテーブルの作成
もう一度Snowflakeに戻り、データを取り込むためのステージとテーブルを作成します。
ステージはストレージ統合を参照しており、取り込むデータのS3パスを設定します。
ストレージ統合ではS3へのアクセス権限が付与されており、ステージにはS3のパスが設定されているということですね。
-- ステージの作成 CREATE STAGE hoge_stage STORAGE_INTEGRATION = hoge URL = 's3://<取り込むデータがあるパス>/'; -- テーブルの作成 CREATE TABLE hoge_table( aaa varchar, bbb varchar, ~~~ zzz varchar);
Snowpipeの作成
ここでようやくSnowpipeの作成。
hoge_stageからhoge_tableへデータをロードしましょう。
CREATE PIPE XXX.PUBLIC.hoge_pipe AUTO_INGEST=TRUE AS COPY INTO XXX.PUBLIC.hoge_table FROM @XXX.PUBLIC.hoge_stage FILE_FORMAT = (TYPE = 'CSV' compression = 'GZIP' field_delimiter = ',' skip_header = 1 FIELD_OPTIONALLY_ENCLOSED_BY='\042');
S3バケットのイベント通知の作成
最後にS3バケットへのファイル作成をトリガーにSnowpipeへのデータロードを行う設定です。
必要となるARN(notification_channel)の取得をしましょう。
SHOW PIPES LIKE 'hoge_pipe';

S3バケットのイベント通知の作成をします。
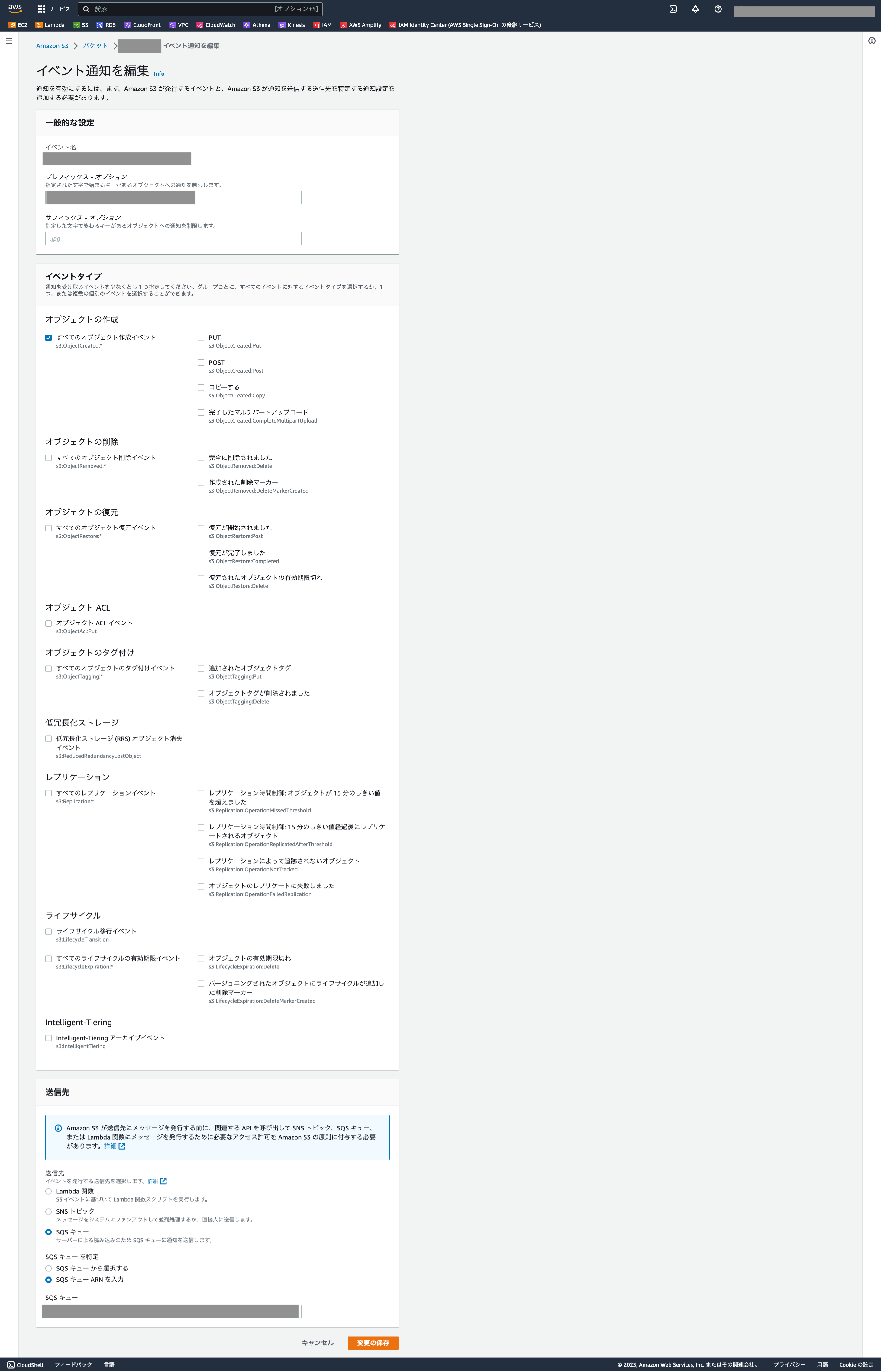
「オブジェクトの作成」を選択し、SQSキューのARNとしてnotification_channelを設定します。
これでSnowpipeの設定は完了です。
すでにS3にファイルが保存されている場合は、COPY INTOコマンドにより手動でデータロードしておきましょう。
COPY INTO XXX.PUBLIC.hoge_table FROM @XXX.PUBLIC.hoge_stage FILE_FORMAT = (TYPE = 'CSV' compression = 'GZIP' field_delimiter = ',' skip_header = 1 FIELD_OPTIONALLY_ENCLOSED_BY='\042');
まとめ
Snowpipeを利用したSnowflakeへのデータロード方法についてまとめました。
ストレージ統合やステージなどSnowlfake特有の設定が最初は複雑に感じるかもしれません。
しかし、Snowpipeは一度設定すれば継続してデータを取り込んでくれるので非常に便利です。
また、データロード時のエラーを検知し、Slack等へ通知することも可能。
取りこぼしに気付くためにも運用時には設定しておきたいですね。
