
GoogleスプレッドシートのデータをBigQueryに取り込むパターン
Google スプレッドシートとBigQuery
ゴールデンウィークも明けまして皆様いかがお過ごしでしょうか。
私はGoogle Cloud Next’24から帰国後の文字通りの「バタバタ」が落ち着いてきたところです。
Google Workspaceを活用している企業においてはスプレッドシートも活用されている方々も多いかと思われます。
10年くらい前(G Suiteのとき)は、「言うてもOfficeがローカルにないと不安やわ〜」な人が大半だった印象ですが、最近は「Officeを入れない」という選択肢もだいぶ現実味を帯びる…というよりスプレッドシートじゃないと困る、くらいになってきました。
そんなGoogle スプレッドシートですが、やはり活用が進めば進むほど、そこにあるデータをBigQueryに取り込みたくなるシーンがあります。
本記事ではそうなった場合にどういった対応があり得るのかを考えます。
取込パターン① 直接外部データとして参照する
あまり知られていない話(?)ですが、 BigQuery自体から直接外部データとしてスプレッドシートを参照することが出来ます。
シート内の範囲指定で対応出来るので、ちょっとくらい上のほうの行に説明文など取込対象外の情報があっても対応出来ます。
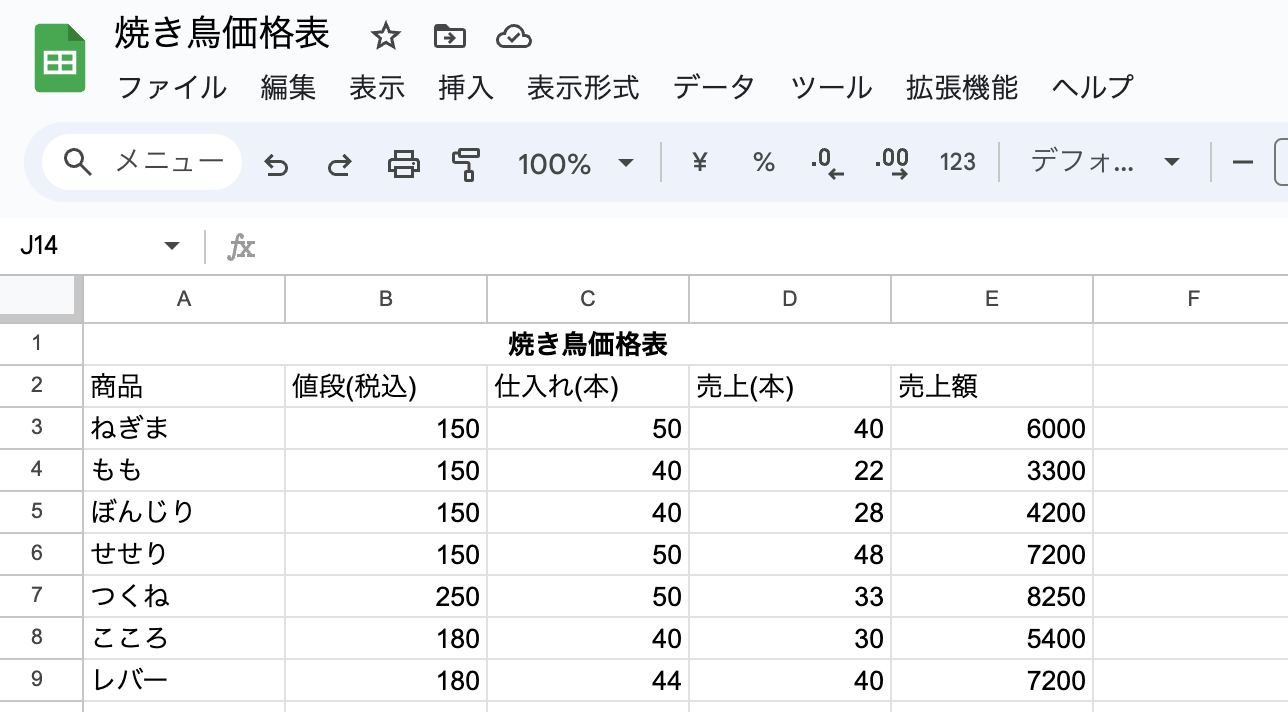
たとえば、こんな感じのスプレッドシートがあったとします。(ネタは適当に食べたいものを挙げました)
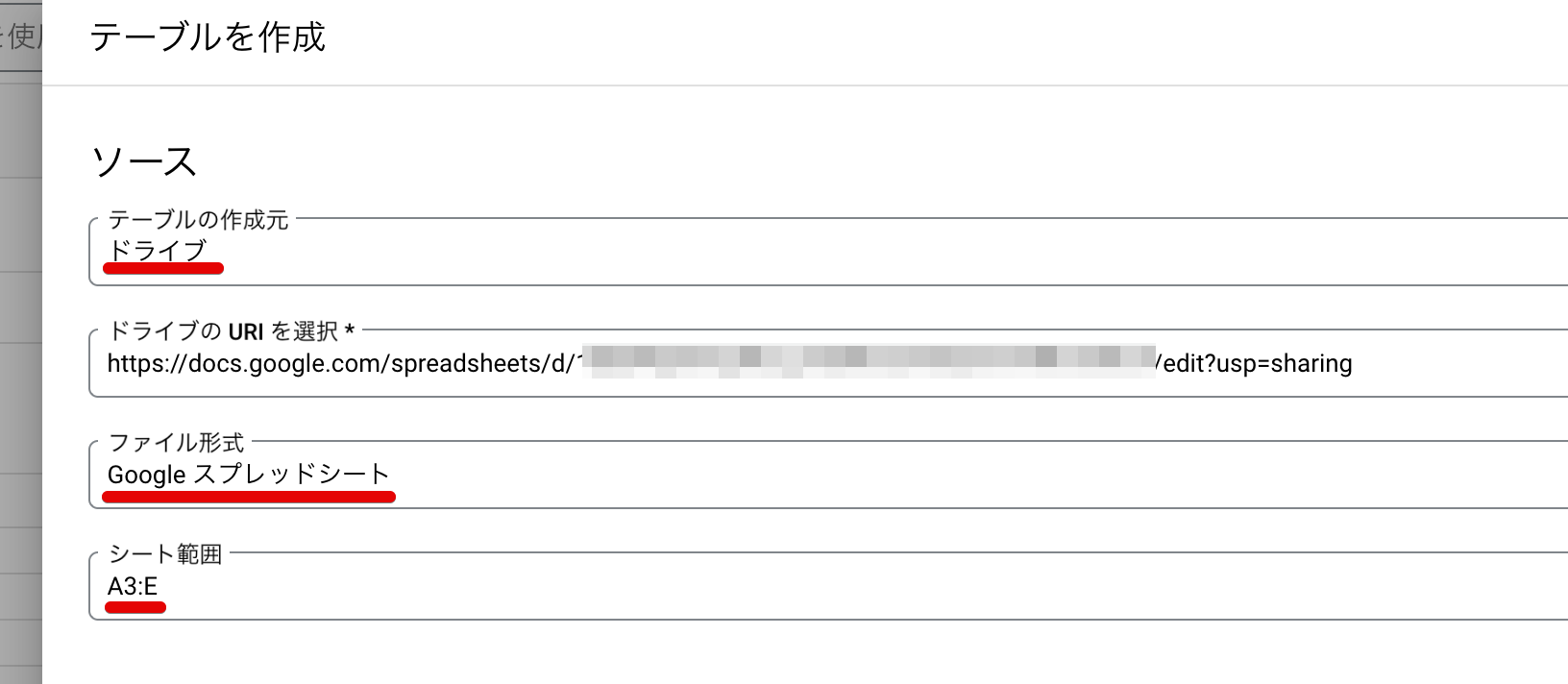
BigQueryで、テーブルを作成する際にテーブルの作成もととして「ドライブ」を選択し、
URIを入れてファイル形式としては「Google スプレッドシート」、そしてシート範囲を指定するだけです。シート範囲はもちろんシート名つきで指定もできます。(指定が無い場合は最初のシートになります)
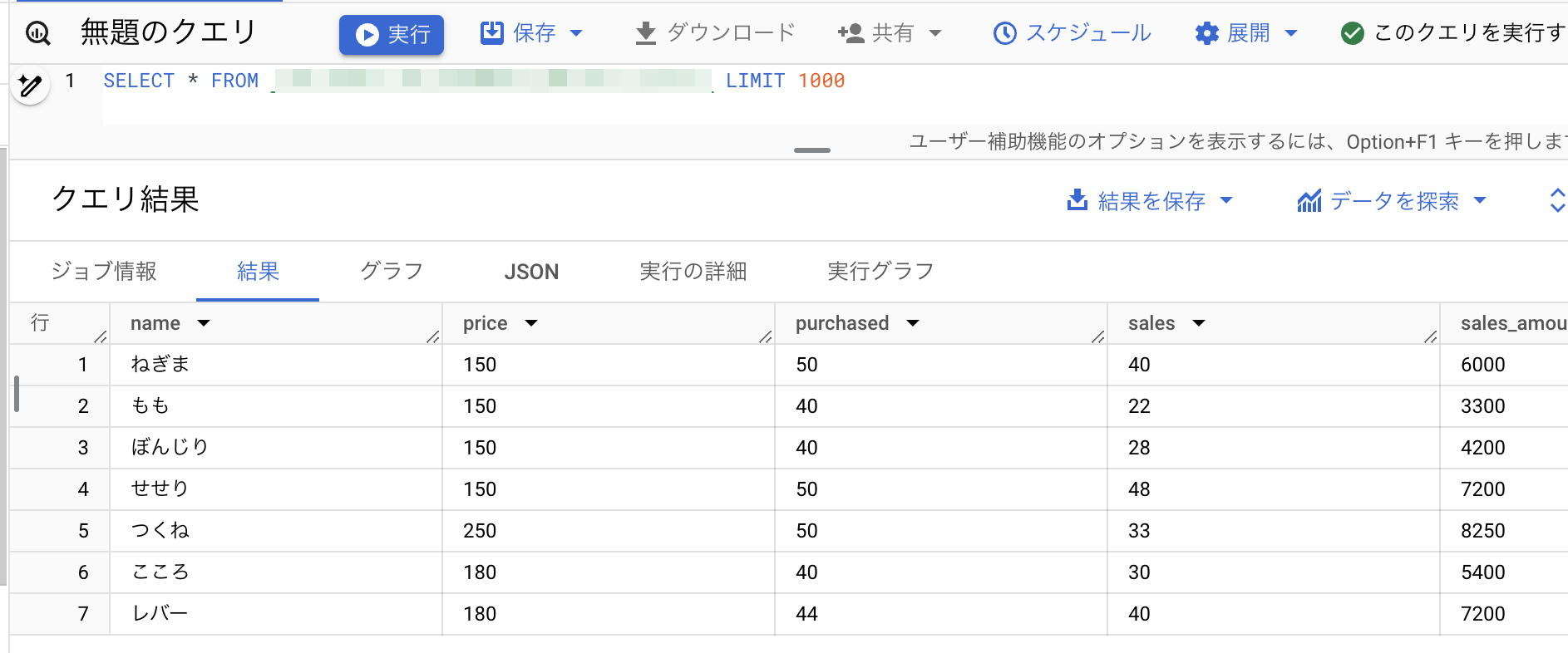
これだけで、問題無く取り込めて、クエリが走ります。
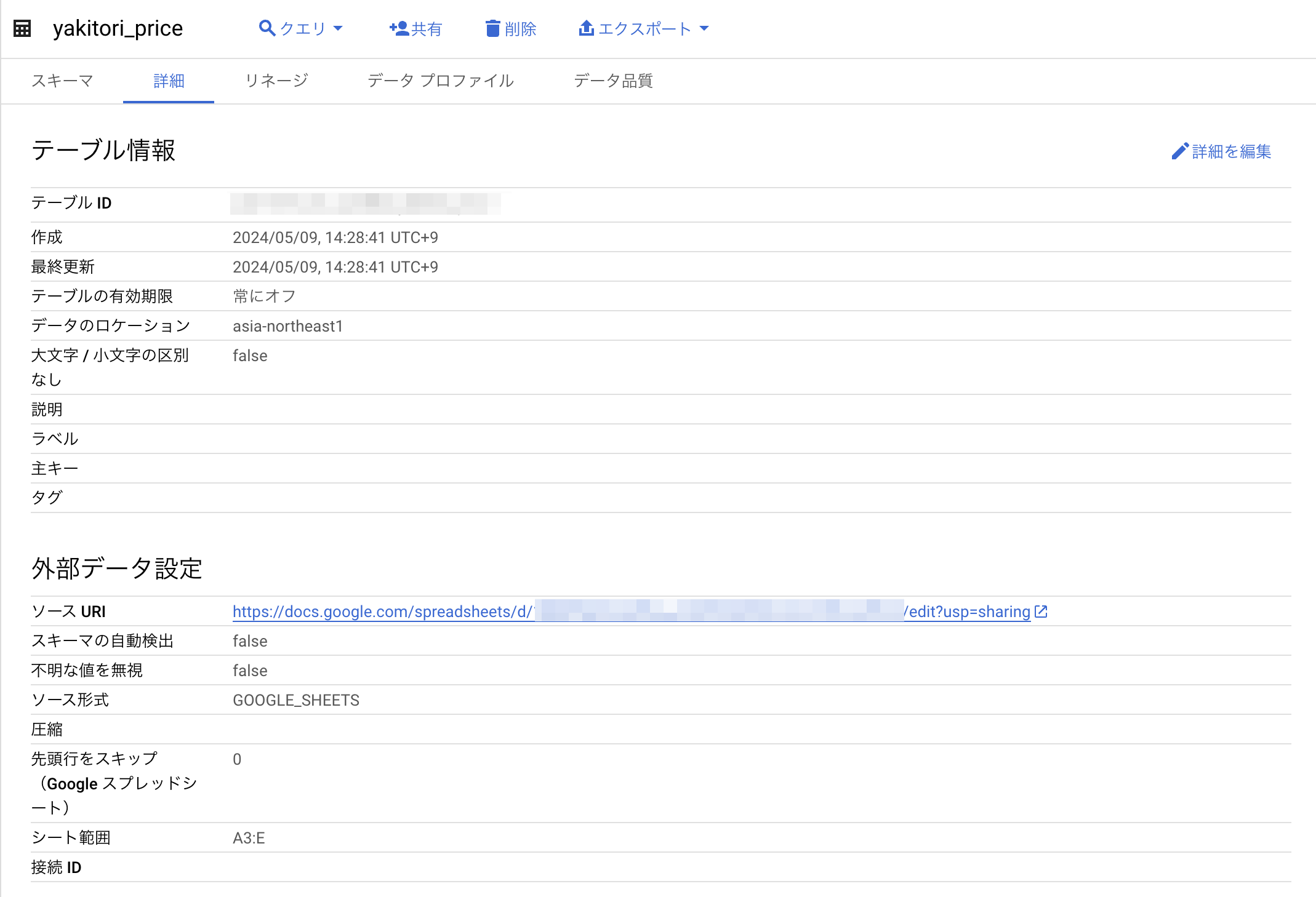
BigQueryでテーブルを表示するとこんな感じです。(プレビューはありません)
と、まあ、こんな感じで、データを取り込むだけであれば直接指定してからTransform(整形加工)していく…みたいな考え方で充分コト足りることも多いのではないかと思います。
ただし、Cloud ComposerやLooker等からクエリを実行する場合サービスアカウントからクエリを叩くことになり、そのサービスアカウントに当該シートの閲覧権限がなければ参照できないことに注意が必要です。
つまり、 クエリを叩いている人やサービスアカウントにスプレッドシートの閲覧権限が必要ということです。
取込パターン② Google Drive APIを使用してダウンロードしてBigQueryにLoadする
しかし、①の方法ではソースURIは一つしか指定できないため「複数の大量ファイルを一気に取り込みたい」といったケースなどには対応出来ません。
そういった場合には、Google DriveのAPIを使ってファイルを一時ディレクトリなどにダウンロードして加工してロード…という方法をとるようにしています。
Pythonでいうと、 google-api-python-client を入れた上で、サービスアカウントのcredentialsを使って
from googleapiclient.discovery import Resource, build credentials = (サービスアカウントのcredentials情報) service = build("drive", "v3", credentials=credentials)
のようにしてGoogle Drive APIを叩く準備をしたあとに、MIME Type( mime_type )や接頭辞 (from_date)、更新日時の下限(from_date )などを指定したうえでクエリしてファイルを抽出します。
※このとき、Google Drive側でサービスアカウントのメールアドレスを閲覧者(ダウンロード可能なもの)として指定するのを忘れないよう注意が必要です。
drive_id = (当該サービスアカウントに共有されている共有ドライブのID) conditions = [ f"'{folder_id}' in parents", "trashed=false", ] if mime_type: conditions.append(f"mimeType='{mime_type}'") if starts_with: conditions.append(f"name starts with '{starts_with}'") if from_date: conditions.append(f"modifiedTime > '{from_date.isoformat()}'") query = " and ".join(conditions) results = ( service.files() .list( driveId=drive_id, corpora="drive", includeItemsFromAllDrives=True, supportsAllDrives=True, q=query, fields="files(id, name, mimeType, modifiedTime)", ) .execute() ) items = results.get("files", [])
これで items の各要素の id キーを参照すればファイルのIDがとれますので、それをもとにダウンロードを行います。
ファイルのIDをもとにダウンロードする関数は下記のように書けます。(この場合は一時ファイルでなくBytesIOに入れています)
from googleapiclient.http import MediaIoBaseDownload def download_file(file_id: str) -> io.BytesIO: """ファイルをダウンロードしてBytesIOで返す Args: file_id (str): ダウンロードしたいファイルのID """ request = service.files().get_media(fileId=file_id) fh = io.BytesIO() downloader = MediaIoBaseDownload(fh, request) done = False while not done: _, done = downloader.next_chunk() fh.seek(0) return fh
あとは適当に加工してGCSにアップロードしてBigQueryにLoad…という手段をとることが多いです。基本的にはストリーミング挿入よりバッチ読み込みのほうが安定していると思います。
こちらのほうが確実ではありますが、実装面で少し時間を掛けざるを得ないのが辛いところですね。取り込む範囲の指定や整形加工処理の実装も必要になりますので少し厄介です。
まとめ
今回はGoogleスプレッドシートをBigQueryに取り込む方法についてまとめてみました。
スプレッドシート単体でも大半のことは実施出来ますが、他のデータとの結合等を行いたければやはりBigQueryに一度取り込んだほうが何かとやりやすいかと思います。
他に何か良い方法があったら記事下部のフィードバックフォーム等から教えていただけると幸いです。
ちなみに逆方向で、スプレッドシートでBigQueryのデータを見ることも出来ます。コネクテッド シートというものですね。
エンジニアの立場からすると全部普通に触れるので基本的にはBigQueryのデータはBigQueryで見る、という運用になりますが、BigQueryを触らせるわけにはいかないようなビジネスユーザなどにはこういった対応を行うこともあり得るかと思いますので知っておくと良いと思います。
